Slow Website?
Check out Luhnar for an easy way to speed up your client's Django, WordPress, or other CMS-based or custom site.
Share this post for much win.
How Async I/O Works
Tuesday, September 18, 2012 » performance
Five Guys sells awesome burgers and fries. Each patty is hand-formed, grilled to order, and piled high with crazy toppings like A1, bacon, and green peppers. Ordering at Five Guys goes something like this:

- You tell Nice Person at the counter what you want to eat.
- Nice Person hands you a receipt with a number on it.
- You take a seat and do something productive, like hack on some code.
- Nice Person takes more orders, sending them to Cook.
- Cook adds patties to the grill as the orders come in, keeping himself busy.
- Nice Person calls your number when your order is ready.
- You pick up your order, return to your seat, and get down to business.
Async I/O works in a similar way:
- Thread tells Kernel what I/O work it wants done (i.e., “please read from this socket” or “please write to this file”).
- Kernel provides a handle to the thread for monitoring the request.
- Kernel adds the request to a list of items to babysit.
- Thread continues on with life, periodically checking1 the I/O handle for events.
- Kernel posts an event to the I/O handle whenever something interesting happens.
- Thread grabs each event, processing it and checking for more events until the requested operation is complete.
Here’s an illustration to help visualize what’s happening:
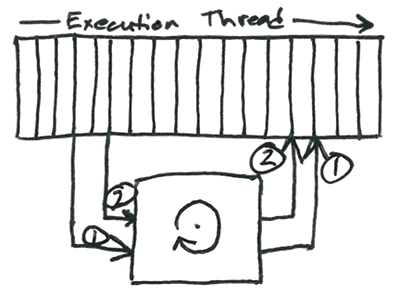
Here we have a (very simplified) execution thread and a fancy box representing the operating system. The thread issues I/O request (1), but since the request is asynchronous, the thread continues working while it waits for the results from (1). In the meantime, the thread issues a second I/O request (2). Eventually, (2) completes, followed closely by (1), generating two I/O events from the kernel. The thread acts on these event, reading the results from first (2), then (1).
Blocking I/O
When a thread uses blocking I/O calls, the process looks something like this:
- Thread tells Kernel what I/O work is needed.
- Kernel adds the request to a list of items to babysit.
- Kernel pauses Thread.
- Kernel wakes up Thread when the I/O request is complete.
- Thread grabs the results.
Now, contrast the blocking I/O illustration below with the one for async I/O:
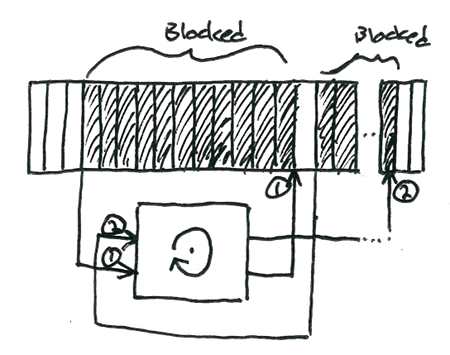
The thread sits idle after issuing I/O request (1). When (1) completes, the thread is allowed to continue its work and issue request (2). Again, this pauses the thread, and the operating system only allows the thread to continue when (2) is complete.
Although blocking I/O is super-simple to use and understand (hooray!), it prevents the thread from doing anything useful whenever an I/O request is pending (booh!). This is really bad; compared to reading and writing RAM, I/O on devices such as HDDs and NICs is excruciatingly slow. Blocking on I/O forces threads into hibernation for millions of CPU-years on every request.
One way of solving the problem is to spawn several worker threads2. For example, you might create two threads, which I’ll cleverly name Thread A and Thread B. These threads listen for incoming HTTP requests. When Client A connects to Thread A, Thread A blocks while it waits for the kernel to read data from the NIC. Meanwhile, Thread B accepts a connection from Client B and starts servicing it. Now that both threads are busy, what happens when a third client wants to talk? Tragically, the kernel is forced to hold the third request in a queue until one of the threads is free. If too many requests pile up, they will time out before they reach the other end of the queue. Worse, if requests continue to arrive faster than they can be processed, the kernel’s queue will eventually fill up, causing the system to block all new connections to the box.
This would be like Five Guys forcing me to stand in line while every single order, for every single person in front of me, is cooked and bagged. Sure, I can check Facebook on my iPhone while I wait, but that hardly counts as being productive. Eventually, I may get so frustrated at waiting that I give up and walk out. This is not good for business (unless you happen to manage the restaurant next door).
In situations like these, asynchronous I/O is exactly what you need. In the above scenario, async functions allow each thread to continue accepting requests, while waiting for bits to travel over the wire. In this way, requests are multiplexed across individual threads of execution, so they spend a lot less time sitting idle, and a lot more time warming the CPU. More clients are served more quickly, with lower latency.
But all is not roses and puppy dogs, my friend.
I/O Bound vs. CPU Bound
If your app spends most3 of its time waiting on disk or network I/O, an asynchronous design will usually improve CPU utilization and reduce latency vs. a synchronous model. I say usually, because async I/O doesn’t help much when your app is only processing a few concurrent tasks. Indeed, some async frameworks come with a significant performance tax that can actually cause higher per-request latency vs. more traditional, synchronous frameworks. This tax only makes sense when you are trying to scale up to thousands of simultaneous, I/O bound tasks. Under heavy load, multiplexing requests across a small number4 of processes drastically increases the maximum number of concurrent requests a box can handle. Each process can jump back and forth between servicing different requests while waiting for I/O operations to complete in the background.
Some apps, on the other hand, spend most of their time running algorithms and crunching numbers (e.g., audio processing, data categorization, scientific computing, etc.). When a task is CPU bound, async I/O certainly won’t buy you anything, and is likely to make things worse. If a thread is spending most of its time crunching data, you might as well use blocking-IO and avoid paying any per-request performance tax5.
Trade-offs
Hardware limits us on what we can achieve using blocking I/O in a single thread of execution, so we have to invent ways of simulating concurrent execution. No approach is perfect; it’s important to realize this, and research the trade-offs involved in each approach, so that we can make better design decisions.
- 1 Some operating systems use a push model instead, i.e., the kernel interrupts the thread when data is ready or more data is required.
- 2 Multiprocessing is a common alternative to multi-threading on POSIX systems.
- 3 All applications require CPU time, which is why it can be helpful to run multiple threads (or processes) if you’ve got the cores.
- 4 Running only one thread or process per CPU minimizes expensive context-switching.
- 5 For this reason, servers that need to perform non-trivial processing on a request should hand off that processing to a worker pool.

{kind=link}